资源
-
Arxiv:[1903.12473] Shape Robust Text Detection with Progressive Scale Expansion Network (arxiv.org)
-
MindOCR:configs/det/psenet/README_CN.md · MindSpore Lab/mindocr - Gitee.com
-
PapersWithCode:Shape Robust Text Detection with Progressive Scale Expansion Network | Papers With Code
全文
Abstract
场景文本识别目前仍存在两个挑战:
- 大多数现有技术的算法都需要四边形边界框来准确定位任意形状的文本。
- 彼此接近的两个文本实例可能导致覆盖这两个实例的错误检测。
基于分割的方法可以缓解第一个问题,但通常无法解决第二个挑战。但是我们提出的渐进尺度扩展网络(PSENet)可以精确地检测任意形状的文本实例。
1 Introduction
场景文本识别现有两大方法:
- 基于回归:文本目标通常以具有特定方向的矩形或四边形的形式表示,遇到曲线一般寄。
- 基于分割:基于像素级分类来定位文本实例。然而,很难将彼此接近的文本实例分开。通常,可以基于基于分割的方法来预测覆盖彼此接近的所有文本实例的错误检测。
本文提出了一种新的基于内核的框架,即渐进规模扩展网络(PSNet)。我们的 PSNet 有以下两个好处。首先,作为一种基于分割的方法,PSENet 进行像素级分割,能够精确定位任意形状的文本实例。其次,我们提出了一种渐进尺度扩展算法,使用该算法可以成功识别相邻的文本实例。

(a)是原始图像。
(b)是指基于回归的方法的结果,该方法显示了令人失望的检测结果,因为红框覆盖了绿框中几乎一半以上的上下文。
(c)是传统语义分割的结果,它将 3 个文本实例误认为 1 个实例,因为它们的边界像素是部分连接的。(d)是我们提出的 PSENet 的结果,它成功地识别和检测了 4 个唯一的文本实例。
2 Related Work
介绍了一下其它的场景文本识别的算法并分析其不足。
3 Proposed Method
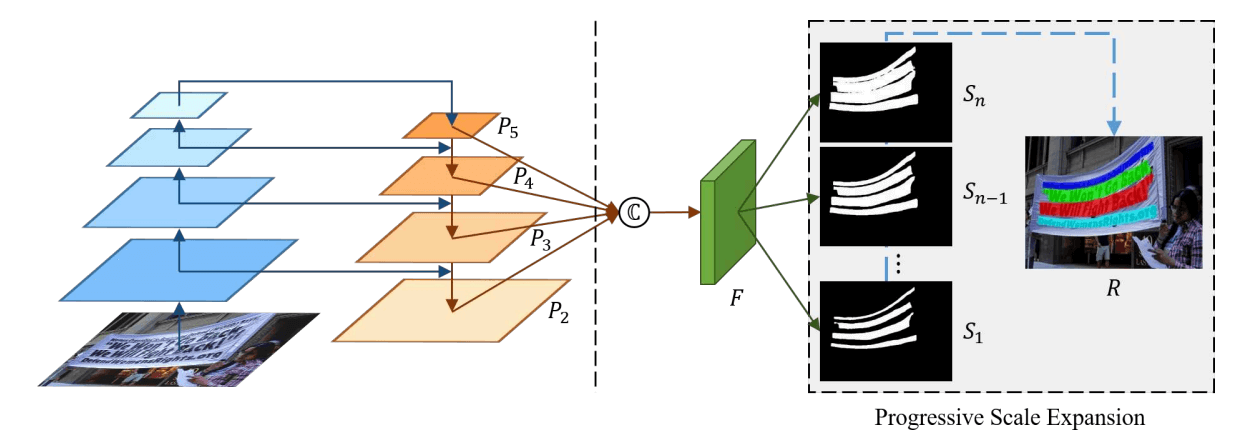
3.1 Overall Pipeline
-
用 ResNet 作为 PSENet 的 backbone
-
将低级纹理特征与高级语义特征连接起来。这些图谱在 中进一步融合,以编码具有各种接受观点的信息
-
这种融合很可能有助于产生各种规模的内核。然后将特征图 投影到 个分支中以产生多个分割结果 、、...,每个 将是在一定尺度上用于所有文本实例的一个分割掩码
-
使用渐进尺度扩展算法将 中的所有实例的核逐渐扩展到 中的完整形状,并获得最终的检测结果作为
3.2 Network Design
PSENet 的基本框架是从 FPN(特征金字塔)中实现的。我们首先从主干中获得四个 256 通道的特征图(即 、、、)。为了进一步组合从低到高的语义特征,我们通过函数 将四个特征图融合,得到具有 1024 个通道的特征图 ,如下所示:
3.3. Progressive Scale Expansion Algorithm
基于分段的方法很难分离彼此接近的文本实例。为了解决这个问题,我们提出了一种渐进的规模扩展算法。
3.4Label Generation
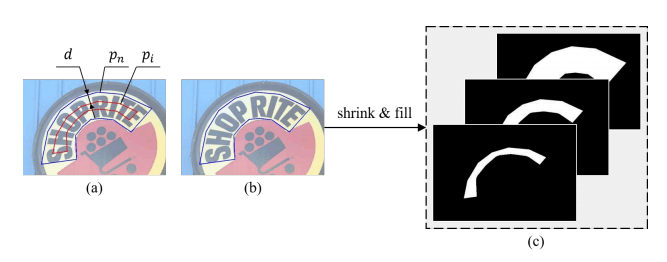
标签生成的图示。 -(a)包含 、 和 的注释 -(b)显示了原始文本实例 -(c)显示了具有不同内核尺度的分割掩码
3.5Loss Function
其中, 和 分别表示完整文本实例和收缩文本实例的损失。
4. Experiment
在最近四个具有挑战性的公共基准上评估了所提出的 PSENet:
- CTW1500
- TotalText
- ICDAR 2015
- ICDAR 2017 MLT (IC17-MLT):多语言,7200 训练集,1800 验证集,9000 测试集
将 PSENet 与最先进的方法进行了比较。
4.1. Datasets
4.2. Implementation Details
-
我们使用在 ImageNet 上预先训练的 ResNet 作为 backbone
-
利用随机梯度下降(SGD)对所有网络进行了优化
-
我们使用 7200 幅 IC17-MLT 训练图像和 1800 幅 IC17-MLT 验证图像来训练模型,并在 IC17-MLT 上报告结果。请注意,没有采用额外的数据,例如 SynthText 来训练 IC17-MLT
-
在 IC17-MLT 上训练 PSENet,在 4 个 GPU 上使用批量大小为 16 的 PSENet 进行 180K 迭代
-
初始学习率设置为 ,在 60K 和 120K 次迭代时除以 10
其余数据集中采用了两种训练策略:
- 从头开始训练
- 在 4 个 GPU 上训练批量大小为 16 的 PSENet 进行 36K 迭代,初始学习率设置为 ,并在 12K 和 24K 迭代时除以 10。
- 对IC17MLT模型进行微调。当对 IC17-MLT 模型进行微调时,迭代次数为 24K,初始学习率为 1×10−4,在 12K 迭代时除以 10。
在训练过程中,我们忽略了所有数据集中标记为“不在乎”的模糊文本区域。损耗平衡的 设置为 0.7。OHEM 的正负比设置为 3。
训练数据的数据扩充如下:
- 图像以 的比率随机重新缩放
- 图像在 范围内水平翻转和旋转
- 从变换后的图像中裁剪 640×640 个随机样本。对于四边形文本,我们计算最小面积矩形来提取边界框。对于曲线文本数据集,应用 PSE 的输出来产生最终结果。
4.3. Ablation Study
4.4. Comparisons with State-of-the-Art Methods
| Method | Ext | P | R | F | FPS |
|---|---|---|---|---|---|
| PSENet-1s | 80.57 | 75.55 | 78.0 | 3.9 | |
| PSENet-1s | 是 | 84.84 | 79.73 | 82.2 | 3.9 |
| PSENet-4s | 是 | 82.09 | 77.84 | 79.9 | 8.4 |
CTW1500 上的结果。“P”、“R” 和 “F” 分别表示精度、召回率和 F-测度。“1s”和“4s”表示输出映射的宽度和高度分别为输入测试图像的 1/1 和 1/4。“Ext” 表示外部数据。
| Method | Ext | P | R | F | FPS |
|---|---|---|---|---|---|
| PSENet-1s | 81.77 | 75.11 | 78.3 | 3.9 | |
| PSENet-1s | 是 | 84.02 | 77.96 | 80.87 | 3.9 |
| PSENet-4s | 是 | 84.54 | 75.23 | 79.61 | 8.4 |
TotalText 的结果。
5. Conclusion and Future Work
好使。